flowchart TB
A[Corpus of documents] --> B[Document-feature matrix<br>'Bag of Words']
B --> C[Supervised<br>known categories]
B --> D[Unsupervised<br>unknown categories]
C --> E[Dictionary &<br>Sentiment]
C --> F[Wordscores &<br>Classifiers]
D --> G[Topic Models]
D --> H[Wordfish]
B --> I[Word Embeddings<br>Word2Vec, GloVe]
I -.-> J[Transformers<br>Attention mechanism]
J -.-> K[Large Language<br>Models]
style A fill:#b8d4e8,stroke:#333
style B fill:#b8d4e8,stroke:#333
style C fill:#b8d4e8,stroke:#333
style D fill:#b8d4e8,stroke:#333
style E fill:#b8d4e8,stroke:#333
style F fill:#b8d4e8,stroke:#333
style G fill:#b8d4e8,stroke:#333
style H fill:#b8d4e8,stroke:#333
style I fill:#b8d4e8,stroke:#333
style J fill:#f0e68c,stroke:#333
style K fill:#f0e68c,stroke:#333
Introduction to AI-assisted Text Analysis with quallmer
LLM for Text Analysis Masterclass at Griffith University
Seraphine F. Maerz
2026-07-20
About This Workshop
Goals:
- Understand basics of LLM-based text analysis
- Learn the core workflow of the quallmer tool (5 steps)
- Replicate a real research example
- Start using quallmer for your own projects
- Know how to validate and document your analysis
Materials
Detailed documentation of the tool: quallmer.github.io/quallmer
Slides and tutorial available on QuantLab website: quantilab.github.io
About Me
- Senior Lecturer in Political Science (Research Methods) at University of Melbourne
- Research: Democracy, authoritarianism, language of political leaders
- Co-founder of QuantLab
- Developer of quallmer (with Ken Benoit)
Motivation: Fight for democracy, making quantitative methods more accessible
Website: seraphinem.github.io
Workshops on instats on AI-assisted text analysis and fine-tuning LLMs
Introduction
LLMs as Qualitative Analysis Tools: Recent Contributions
A growing body of research demonstrates LLMs’ potential for qualitative text analysis:
Benoit et al. (2026): Using LLMs to analyze political texts through natural language understanding. American Journal of Political Science. LLM-generated party position estimates correlate highly with expert ratings – scalable alternative to human coders.
Halterman and Keith (2025): Codebook LLMs: Evaluating LLMs as measurement tools for political science concepts. Political Analysis. Systematic evaluation of LLMs for coding political science concepts with codebook guidance.
Hayes (2025): “Conversing” with qualitative data. International Journal of Qualitative Methods. LLMs enable researchers to explore qualitative data in a conversational way.
Emerging Consensus
LLMs can complement (not replace!) traditional methods – but require validation, transparency, and methodological rigor.
The Quant-Qual Dilemma
Quantitative
- Large N, generalizability
- Replicable & transparent
- Statistical rigor
But: Lacks depth, context, nuance
Qualitative
- Rich detail & context
- Captures complexity
- Discovers unexpected patterns
But: Small N, labor-intensive, harder to generalize
LLMs as a Bridge?
LLMs could combine scale & replicability with contextual understanding — but only if:
- Results are validated against human judgment
- The process is transparent and documented
- We maintain audit trails for rigor and replicability
quallmer was developed with this vision — grounded in established insights from qualitative research methodology.
Quality in Qualitative Research


Lincoln & Guba’s (1985) trustworthiness criteria and the importance of audit trails for transparency and rigor in qualitative research, Seale, C. (1999). Guiding ideals. In The Quality of Qualitative Research (pp. 32-50). SAGE Publications Ltd.
From Bag of Words to LLMs
Pre-LLM Text Analysis
Pre-LLM vs. LLM Approaches
Traditional:
- Dictionary methods
- Topic models
- Supervised learning
LLM-based:
- Zero-shot classification
- Context-aware
- Can explain reasoning
All (text) models are wrong – but some are useful!
Why Use LLMs for Research?
| Challenge | Traditional | LLM-Based |
|---|---|---|
| Context | Limited | Strong |
| Training data | Often needed | Usually not |
| Cost | Can be high | Variable (depends on API) |
| Nuance | Struggles | Better |
| Reproducibility | Strong | Not 100% |
Important
LLMs produce language – not truth! Validation is essential.
Data Security & Ethical Considerations
Key concerns when using LLMs:
- Privacy – Sensitive data uploaded to external servers (closed LLMs)
- Reproducibility – Same prompts can give different responses
- Bias & fairness – Models may reflect training data biases
- Transparency – Training data often unknown (closed LLMs)
- Resource consumption – Environmental impact of large models
Reminder: Use open-source LLMs for sensitive data; provide traceability; always validate!
Current Landscape of LLM Tools for Text Analysis
Existing Tools
Proprietary QDA software (NVivo, MAXQDA, QDAMiner) have added AI-assisted coding, but:
- GUI-only – No code-based workflow, analyses cannot be executed as code
- Not reproducible – Results cannot be straightforwardly replicated
- No comprehensive audit trails – Partial documentation at best
- Opaque models – NVivo/MAXQDA don’t disclose which model powers their AI
- Not open-source
Custom LLM code gives flexibility, but researchers must build infrastructure from scratch:
- Managing codebooks
- Tracking provenance
- Computing reliability metrics
- Documenting workflows
This can distract from substantive research questions.
Working with LLMs in R
General-purpose R packages for LLM access:
ellmer(Wickham et al., 2025)ollamar(Lin & Safi, 2025)rollama(Gruber & Weber, 2024)
Flexible LLM interfaces – but no qualitative methodology / text analysis support.
Text analysis packages:
quanteda(Benoit et al., 2018) – quantitative text analysis, not AI-assisted qualitative coding
The Gap
No existing tool addresses the specific methodological requirements of trustworthy qualitative research with LLMs.
Introducing quallmer
What is quallmer?
![]()
An R package that enables researchers to apply LLM-assisted qualitative coding while maintaining the rigorous standards of transparency and traceability essential to qualitative research.
Key features:
- Works with texts, images, PDFs, audio, and tabular data
- Supports open-source and proprietary LLMs (OpenAI, Anthropic, Hugging Face, etc.)
- Built on the
ellmerpackage (Wickham et al., 2025) - Co-developed by Seraphine Maerz and Kenneth Benoit
- Available on CRAN:
install.packages("quallmer")
The quallmer Philosophy
Simplicity & Accessibility
- Minimal code required
- Clear, intuitive workflow
- Designed for newcomers to R
- Comprehensive tutorials and documentation
Rigor & Transparency
- Built-in validation tools
- Automatic audit trails
- Full traceability of decisions
- Reproducible analyses
Getting Started
Step-by-step tutorials available at quallmer.github.io/quallmer
The 5-Step Workflow
| Step | Function(s) | Purpose |
|---|---|---|
| 1. Define codebook | qlm_codebook() |
Create reusable coding schemes with instructions and structured output schema |
| 2. Code data | qlm_code() |
Apply codebook to texts, images, PDFs, audio, or tabular data using any supported LLM |
| 3. Replicate | qlm_replicate() |
Re-run coding with different models or parameter settings, preserving provenance chains |
| 4. Compare & validate | qlm_compare(), qlm_validate() |
Compute inter-rater reliability metrics; benchmark against human-coded gold standards |
| 5. Audit trail | qlm_trail() |
Generate complete audit documentation and executable replication report |
Example: Coding Political Speeches
The Research Question
Original Study: Maerz & Schneider (2020), Quality & Quantity
- Corpus of 4,740 speeches by 40 heads of government in 27 countries
- Finding: Autocratic leaders use more illiberal language; some democratic leaders too (correlation with backsliding)
Goal: Replicate using LLMs instead of dictionary/topic model approach
- Can LLMs identify liberal-illiberal rhetoric?
- Do they correlate with human/dictionary codings?
Step 1: Define the Codebook
library(quallmer)
codebook_ideology <- qlm_codebook(
name = "Liberal-illiberal rhetoric",
instructions = "Analyze the rhetorical style of this political speech.
ILLIBERAL rhetoric (negative scores): nationalism, paternalism, traditionalism.
LIBERAL rhetoric (positive scores): individual rights, tolerance, civil liberties.
Score 0 = neutral/mixed.",
schema = type_object(
score = type_integer("Score from -10 (illiberal) to +10 (liberal)"),
explanation = type_string("Brief explanation of the score")
)
)The schema defines the structured output – here, the LLM returns both a score and an explanation.
Schema Options
The schema defines what the LLM returns:
| Type | Use for | Example |
|---|---|---|
type_integer() |
Fixed categories | c("pos", "neg", "neutral") |
type_string() |
Text/explanations | "Brief explanation" |
type_number() |
Number scores | -10 to +10 |
type_boolean() |
Yes/no questions | TRUE/FALSE |
type_array() |
Lists of items | Persons, relationships, things, etc. |
Tip
The schema is flexible – you can ask for multiple fields and also nest objects for more complex outputs – it can be nicely tailored to your research question. Think carefully about what you want to get back from the LLM, the schema will guide the response format and content!
Step 2: Code the Data
Returns a qlm_coded object with:
- Coding results (score, explanation)
- Full metadata (timestamps, model identifiers, codebook used)
Step 3: Replicate
Provenance chains link replicated results to their parent analyses.
Step 4: Compare & Validate
Metrics available:
- Krippendorff’s alpha, Cohen’s kappa, Fleiss’ kappa
- Accuracy, precision, recall, F1 scores
For manual review and spot-checking, use the companion quallmer.app Shiny application – see tutorials for details.
Results: LLM vs. Dictionary Scores
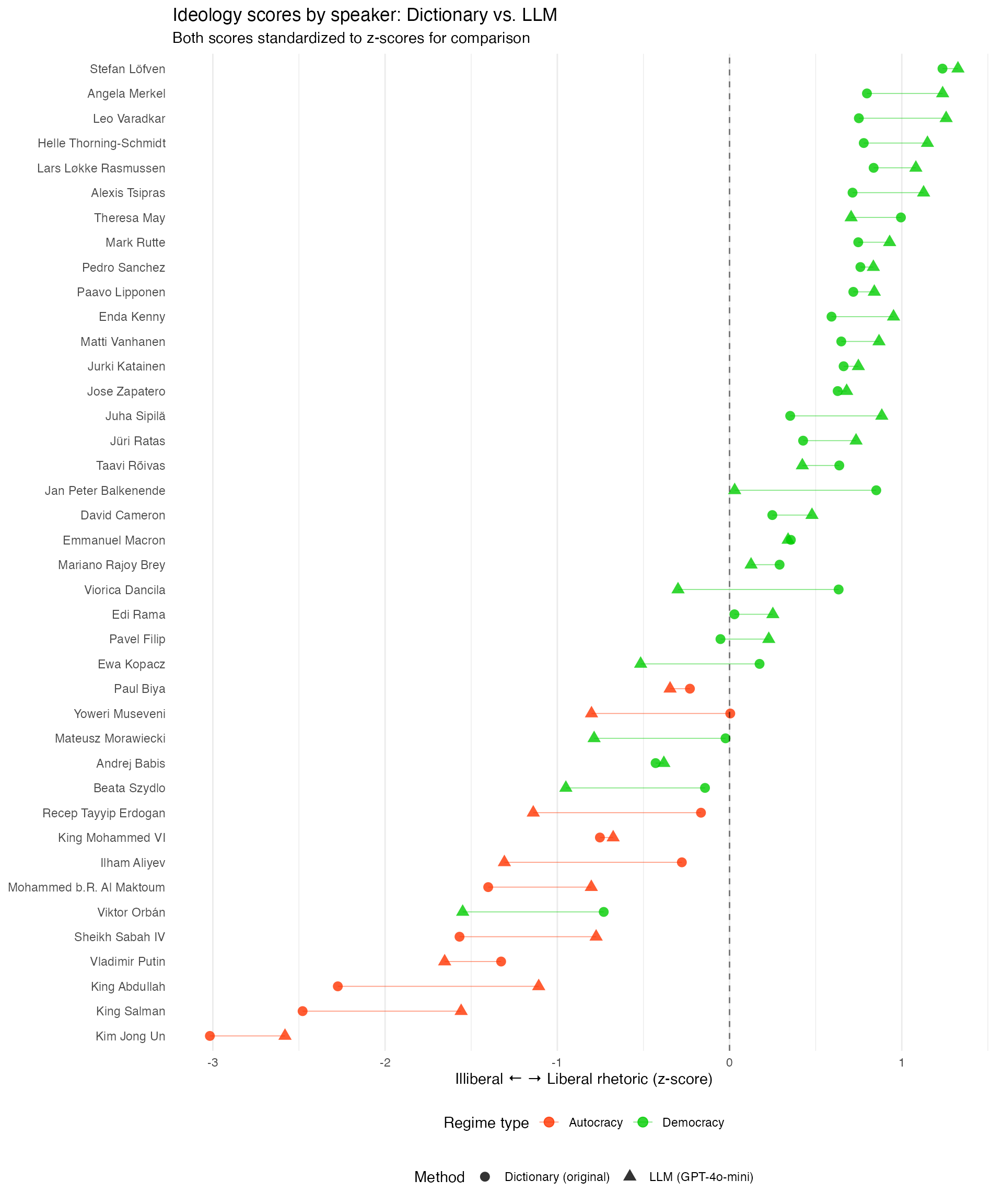
LLM advantages:
- Replicates dictionary results fast and cost-effectively
- Provides explanations for each score
- Enables cross-model validation
Step 5: Audit Trail
Following Lincoln & Guba (1985), the audit trail includes:
- Instrument development (codebook definition)
- Process notes & decisions (model parameters, timestamps)
- Parent-child relationships across analyses
- Complete replication code
Best Practices
Validation is Key!
Three types:
- Gold standard – Compare to human codings
- Intercoder reliability – Compare multiple LLMs
- Manual review – Spot-check outputs with quallmer.app
Open vs. Closed LLMs
Closed (OpenAI, Claude)
- Higher performance
- User-friendly
- Privacy concerns
Open (Llama, Ollama)
- Full control
- Better for sensitive data
- More reproducible, fine-tuning options
quallmer supports both!
Tips for Good Codebooks
- Be specific – Define categories clearly
- Provide examples – Show what each category looks like
- Use scales wisely – Ordinal vs. categorical
- Include explanation – See the LLM’s reasoning
- Iterate – Test and refine
Questions? Break?
![]()
Coming up next:
- Hands-on tutorial
- Replicating a real research example
- Starting your own project with quallmer
Were you able to prepare for the tutorial? (Installing R/RStudio, Ollama, openai API key?)
- Takes 10-15 minutes to set up if you haven’t already – instructions available at QuantLab website: quantilab.github.io / Sharezone
![]()
quallmer.github.io/quallmer