flowchart TB
A[Corpus of documents] --> B[Document-feature matrix<br>'Bag of Words']
B --> C[Supervised<br>known categories]
B --> D[Unsupervised<br>unknown categories]
C --> E[Dictionary &<br>Sentiment]
C --> F[Wordscores &<br>Classifiers]
D --> G[Topic Models]
D --> H[Wordfish]
B --> I[Word Embeddings<br>Word2Vec, GloVe]
I -.-> J[Transformers<br>Attention mechanism]
J -.-> K[Large Language<br>Models]
style A fill:#b8d4e8,stroke:#333
style B fill:#b8d4e8,stroke:#333
style C fill:#b8d4e8,stroke:#333
style D fill:#b8d4e8,stroke:#333
style E fill:#b8d4e8,stroke:#333
style F fill:#b8d4e8,stroke:#333
style G fill:#b8d4e8,stroke:#333
style H fill:#b8d4e8,stroke:#333
style I fill:#b8d4e8,stroke:#333
style J fill:#f0e68c,stroke:#333
style K fill:#f0e68c,stroke:#333
Analysing qualitative data with LLMs
An introduction to the quallmer toolbox
Seraphine F. Maerz
2026-07-20
About Me
- Senior Lecturer in Political Science (Research Methods) at University of Melbourne
- Research: Democracy, authoritarianism, language of political leaders
- Co-founder of QuantLab
- Developer of quallmer (with Ken Benoit)
Motivation: Fight for democracy, making quantitative methods more accessible
Website: seraphinem.github.io
About This Workshop
Goals:
- Understand how quallmer can help you use LLMs for qualitative coding
- Learn the core workflow (5 steps)
- Demo: Replicate a real research example
- Know how to validate and document your analysis
The Quant-Qual Dilemma
Quantitative
- Large N, generalizability
- Replicable & transparent
- Statistical rigor
But: Lacks depth, context, nuance
Qualitative
- Rich detail & context
- Captures complexity
- Discovers unexpected patterns
But: Small N, labor-intensive, harder to generalize
LLMs as a Bridge?
LLMs could combine scale & replicability with contextual understanding — but only if:
- Results are validated against human judgment
- The process is transparent and documented
- We maintain audit trails for rigor and replicability
quallmer was developed with this vision — grounded in established insights from qualitative research methodology.
Quality in Qualitative Research


Lincoln & Guba’s (1985) trustworthiness criteria and the importance of audit trails for transparency and rigor in qualitative research, Seale, C. (1999). Guiding ideals. In The Quality of Qualitative Research (pp. 32-50). SAGE Publications Ltd.
Part 1: Introduction to text analysis with LLMs
Pre-LLM Quantitative Text Analysis
Pre-LLM vs. LLM Approaches
Traditional “text-as-data” approaches:
- Dictionary methods
- Topic models
- Supervised learning
LLM-based:
- Zero-shot classification
- Context-aware
- Can explain reasoning
All (text) models are wrong – but some are useful!
Why Use LLMs for Research?
| Challenge | Traditional | LLM-Based |
|---|---|---|
| Context | Limited | Strong |
| Training data | Often needed | Usually not |
| Cost | Can be high | Variable (depends on API) |
| Nuance | Struggles | Better |
| Reproducibility | Strong | Not 100% |
Important
LLMs produce language – not truth! Validation is essential.
Data Security & Ethical Considerations
Key concerns when using LLMs:
- Privacy – Sensitive data uploaded to external servers (closed LLMs)
- Reproducibility – Same prompts can give different responses
- Bias & fairness – Models may reflect training data biases
- Transparency – Training data often unknown (closed LLMs)
- Resource consumption – Environmental impact of large models
Reminder: Use open-source LLMs for sensitive data; provide traceability; always validate!
Part 2: Introducing quallmer
What is quallmer?
![]()
An R package for AI-assisted qualitative coding – accessible without deep expertise in R or ML.
By: Seraphine F. Maerz & Kenneth Benoit
Available on CRAN:
The quallmer Philosophy
Simplicity
- Minimal code
- Clear workflow
- Made for newcomers to R
Rigor
- Built-in validation
- Audit trails
- Transparency and traceability
The 5-Step Workflow
| Step | Function | Purpose |
|---|---|---|
| 1 | qlm_codebook() |
Define coding scheme |
| 2 | qlm_code() |
Apply LLM coding |
| 3 | qlm_replicate() |
Test robustness |
| 4 | qlm_validate() / qlm_compare() |
Assess validity & reliability |
| 5 | qlm_trail() |
Create audit trail |
Part 3: Example
Illiberalism in Political Speeches
Original Study: Maerz & Schneider (2020), Quality & Quantity: “Comparing public communication in democracies and autocracies”
- Corpus of 4,740 speeches by 40 heads of government in 27 countries
Key Findings:
- Autocratic leaders use more illiberal language
- Some political leaders in formal democracies also use illiberal language (correlation with backsliding)
Our Goal here: Replicate using LLMs instead of a dictionary/topic model approach.
The Data
| speaker | country | year | regime | text |
|---|---|---|---|---|
| Angela Merkel | Germany | 2015 | Democracy | “Today, we are facing a great challenge…” |
| Vladimir Putin | Russia | 2014 | Autocracy | “The West has been trying to encircle us…” |
| Viktor Orbán | Hungary | 2018 | Democracy | “We must protect our borders and our culture…” |
| Kim Jong Un | North Korea | 2019 | Autocracy | “The imperialists are trying to undermine our sovereignty…” |
Note: Example texts are illustrative.
Step 1: Define the Codebook
codebook_ideology <- qlm_codebook(
name = "Liberal-illiberal rhetoric",
instructions = "Analyze rhetorical style of this speech.
ILLIBERAL (negative): nationalism, paternalism, order
LIBERAL (positive): rights, pluralism, rule of law",
schema = type_object(
score = type_integer("Score: -10 to +10"),
explanation = type_string("Brief explanation")
),
role = "You are an expert political scientist."
)Schema Options
The schema defines what the LLM returns:
| Type | Use for | Example |
|---|---|---|
type_integer() |
Fixed categories | c("pos", "neg", "neutral") |
type_string() |
Text/explanations | "Brief explanation" |
type_number() |
Number scores | -10 to +10 |
type_boolean() |
Yes/no questions | TRUE/FALSE |
Tip
The schema is flexible – you can ask for multiple fields and also nest objects for more complex outputs – it can be nicely tailored to your research question. Think carefully about what you want to get back from the LLM, the schema will guide the response format and content!
Step 2: Code the Speeches
API Key Required
Understanding the Output
Each row contains:
- score: LLM’s rating (-10 to +10)
- explanation: Why the score was assigned
| doc_id | score | explanation |
|---|---|---|
| speech_001 | -5 | “Strong nationalist themes…” |
| speech_002 | 7 | “Focus on individual rights…” |
Key advantage: We see why each score was assigned!
Step 3: Replicate
Why replicate?
- LLMs can vary in responses
- Test robustness
- Compare models
Step 4: Validate
Two validation approaches:
# Compare LLM to gold standard (human/dictionary codings)
validation <- qlm_validate(
coded_speeches,
gold = dictionary_coded,
by = "score", level = "interval"
)
# Compare multiple LLM runs/models (inter-rater reliability)
comparison <- qlm_compare(
coded_gpt4o, coded_gpt4omini,
by = "score", level = "interval"
)| Value | Agreement |
|---|---|
| < 0.40 | Poor |
| 0.40-0.60 | Moderate |
| 0.60-0.80 | Substantial |
| > 0.80 | Almost perfect |
Replication Results: Ideology Scale
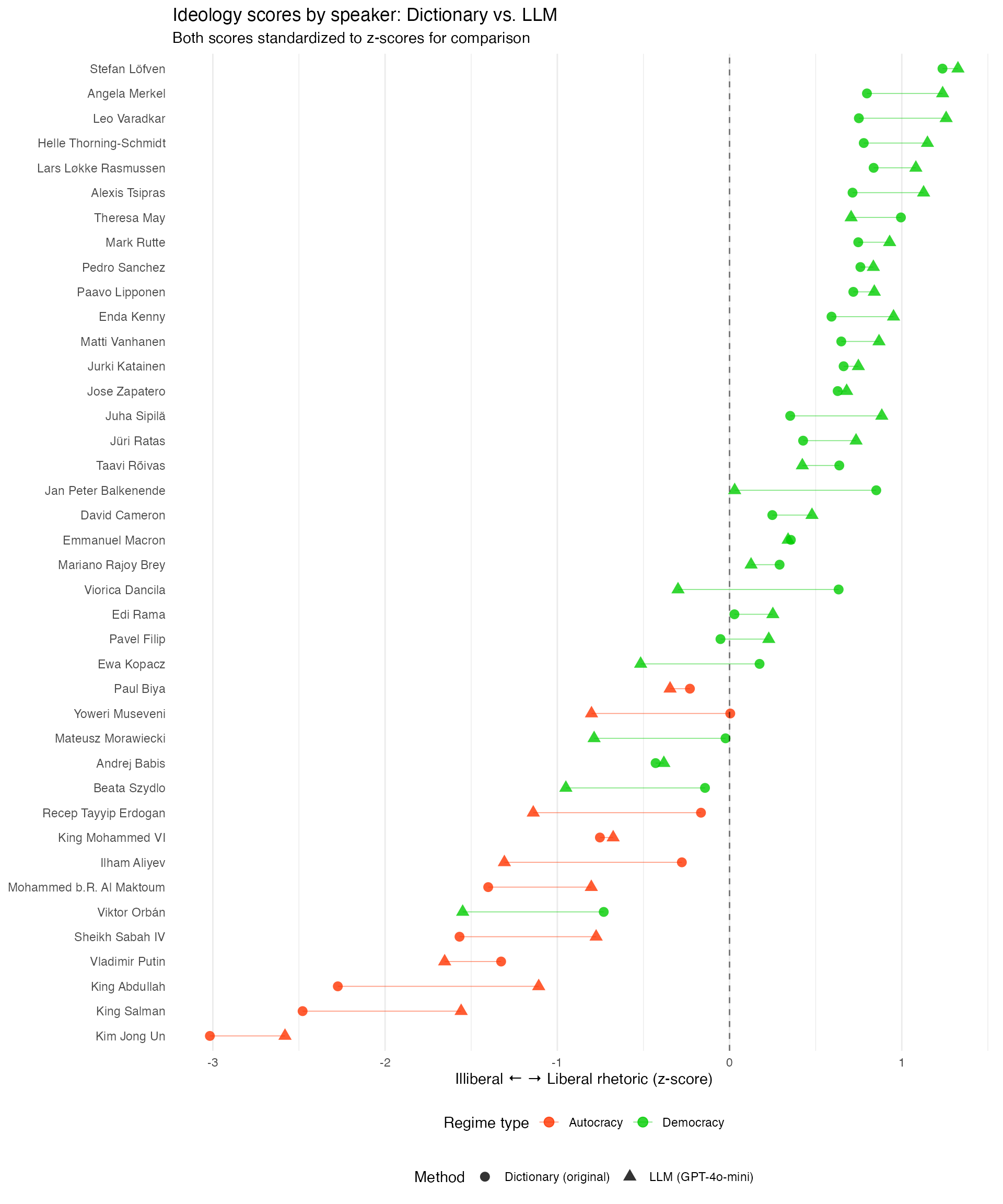
LLM advantages:
- Replicates dictionary results fast and cost-effectively
- Provides explanations for each score
Step 5: Audit Trail
Following Lincoln & Guba’s (1985) trustworthiness framework, the automatically created report includes:
- Instrument development (codebook)
- Process notes & decisions
- Complete replication code
Part 4: Best Practices
Validation is Key!
Three types:
- Gold standard – Compare to human codings (accuracy, precision, recall, F1)
- Intercoder reliability – Compare multiple LLMs (Krippendorff’s alpha, Cohen’s kappa)
- Manual review – Spot-check outputs with quallmer.app, focus on disagreements
Open vs. Closed LLMs
Closed (OpenAI, Claude)
- Higher performance
- User-friendly
- Privacy concerns
Open (Llama, Ollama)
- Full control
- Better for sensitive data
- More reproducible, fine-tuning options
quallmer supports both!
Tips for Good Codebooks
- Be specific – Define categories clearly
- Provide examples – Show what each category looks like
- Use scales wisely – Ordinal vs. categorical
- Include explanation – See the LLM’s reasoning
- Iterate – Test and refine
Summary
Key Takeaways
- quallmer makes LLM coding accessible – 5 functions
- Rigorous workflow – Built-in validation
- LLMs complement traditional methods
- Validation is essential
- Use audit trails for transparency and traceability
Questions?
![]()
- Contact: seraphinem.github.io
- Package website including tutorials: quallmer.github.io/quallmer
Thank You
Happy coding with quallmer!
Next QuantLab on April 28, 12-1pm
Upgrading Policy / Documentation Analysis with AI: Learn how to extract and process information from large policy databases efficiently using AI
with Dr. Jan Kabatek from the Melbourne Institute
Stay tuned for more upcoming sessions of our “AI for Social Science” series:
All welcome!
References
Lincoln, Y. S., & Guba, E. G. (1985). Naturalistic Inquiry. Sage.
Maerz, S. F., & Schneider, C. Q. (2020). Comparing public communication in democracies and autocracies. Quality & Quantity, 54, 517-545.
![]()
quallmer.github.io/quallmer